大语言语言模型安全攻击以及AI供应链漏洞
大语言语言模型安全攻击以及AI供应链漏洞
渊龙Sec安全团队 2024-11-15 11:28
01
简要说明
人工智能和人工智能的安全性正在以惊人的速度发展,AI模型供应链中使用的工具,用于构建机器学习模型,会使AI应用程序容易受到独特的安全威胁。
这些工具是开源的,这意味着它们开箱即用时可能存在漏洞,这些漏洞可直接导致完整的系统接管,例如未经身份验证的远程代码执行或本地文件包含。这意味着什么?您可能面临模型、数据和凭据被盗的风险。
大语言模型因其出色的文本理解和生成能力,被广泛应用于自然语言处理领域并取得了显著成果,为社会各界带来了巨大的便利。然而,大语言模型自身仍存在明显的安全问题,严重影响其应用的可信性与可靠性,是安全学者需广泛关注的问题。
此专题主要目的为拓宽AI与AI供应链安全相关知识,以下内容均为参考论文、博客,拓宽知识面,提升对安全认知的宽度。
02
技术背景
美国人工智能研究实验室 OpenAI 开发出一种可能会改变人类历史的人工智能技术驱动的自然语言处理工具,一种划时代的产物 ChatGPT,ChatGPT 是AI 技术进展的成果,已经获得了代码的理解能力,潜在地获得了复杂推理的能力,可以和人类的常识、认知、需求、价值观保持一致,ChatGPT 在大量的网络文本数据上进行训练。
它的知识和语言表达能力比其他 AI 机器人更加丰富,并且拥有更强的自然语言处理能力,能够理解复杂的语言结构,回答各种类型的问题,知识范围更广更智能,回答更加精确,可以根据用户的语境和问题进行上下文理解,还可以撰写邮件、视频脚本、文案、翻译、代码等任务。
03
大语言模型(LLM)的提示注入攻击

使用“IgnorePrevious
Prompt”命令来指导 LLM 无视之前的指令,这可能被用来绕过内容审查、生成恶意内容。
提示注入攻击主要利用 LLM 在处理文本时常常难以区分系统指令和用户输入的缺陷,这种界限的模糊可能导致恶意指令的成功注入。
LLM 在生成文本时依赖于对自然语言的识别和处理,然而在自然语言中系统指令和用户输入提示词往往混合在一起,缺乏清晰的界限。由于这种模糊性,LLM有可能将系统指令和用户输入统一当作指令来处理,缺乏对提示词进行严格验证的机制,从而因受到恶意指令的干扰而输出具有危害性的内容。
04
大语言模型(LLM)的幻觉问题
大语言模型的幻觉问题指模型在处理输入任务、维持输出语境连贯性以及与现实世界事实保持一致性时存在偏差或错误。
如图所示,大模型的幻觉问题可归结为3种主要表现形式:
1)回答与输入任务不匹配,即模型生成的回答与用户输入的任务不相关;
2)回答内容语境不一致,即模型生成的回答前后矛盾;
3)回答与既定事实相违背,即模型生成的回答与现实世界的可验证事实存在冲突。
这些幻觉问题影响了大模型的可靠性,并限制了大模型的应用范围,尤其是在关键领域如医疗和金融。
05
大语言模型(LLM)的提示词泄露
提示词泄露将导致本属于应用开发者的系统提示词被其他竞争对手用于获利,而为用户定制的提示词被泄露可能导致用户隐私信息被泄露。提示词泄露亦有可能增强其他针对大模型的攻击,例如攻击者可基于被泄露的系统提示词,针对性优化提示词注入攻击的载荷,从而更好地绕过系统提示词 为大模型添加的安全措施。
上图给出了泄露大模型应用的系统提示词,攻击者可向应用发送专门构造的攻击载荷,这些攻击载荷使得大模型忽略提示词的要求,转而执行复述操作,将该应用的提示词返回给攻击者。
06
不安全特性可被利用于AI供应链攻击
腾讯朱雀实验室在对datasets等AI开源组件进行安全研究时发现,开发者通常会使用datasets组件的load_dataset函数加载数据集,为了考虑支持更复杂的数据处理格式或流程,当加载的数据集下包含有与数据集同名的Python脚本时,将会默认运行该脚本。
由于Hugging Face平台上的数据集都由用户上传,如果数据集中的Python脚本包含恶意行为,那么会造成严重的安全风险,如下图所示,攻击者构造的恶意脚本会主动连接攻击者服务器,并等待攻击者下发执行系统命令,最终窃取受害者服务器上的敏感数据。
利用该特性,攻击者可通过在Hugging Face、Github及其他渠道分发包含恶意后门代码的数据集,当开发者通过datasets组件加载恶意数据集进行训练或微调时,数据集里的恶意后门代码将会运行,从而导致AI模型、数据集、代码被盗或被恶意篡改。
作为AI领域的基础库,datasets拥有很大的下载量,根据pypistats网站统计,最近一天下载量将近10万。一旦有恶意数据集在网络上被大范围传播与使用,将会有大量开发者遭受这种供应链后门投毒攻击。
06
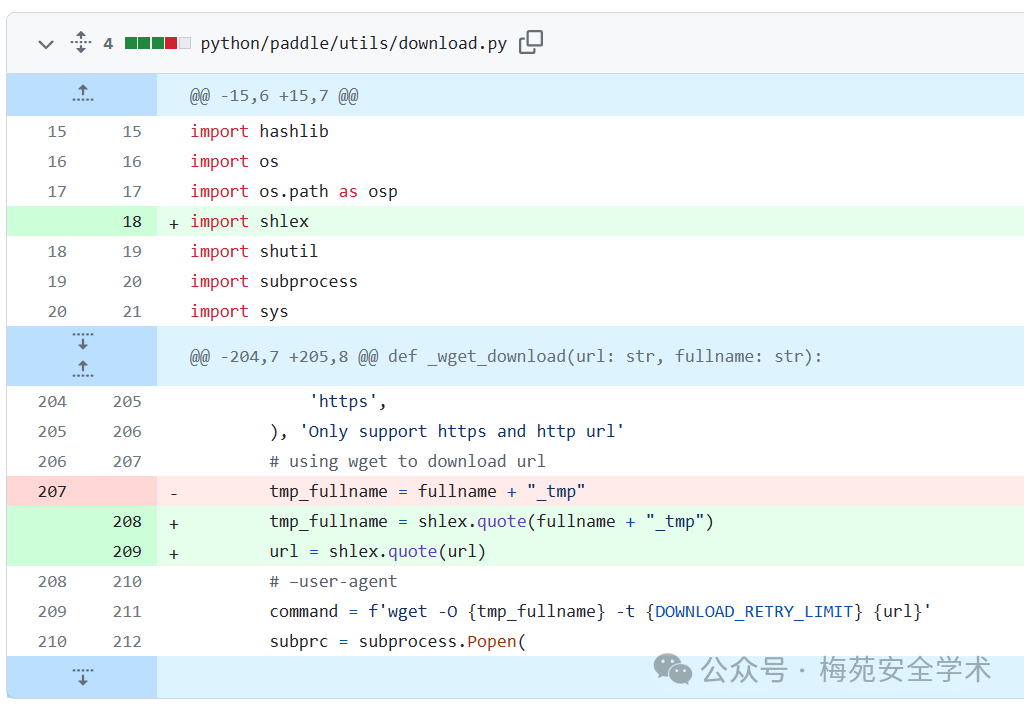
AI供应链漏洞(CVE-2024-0521)
PaddlePaddle作为中国首个自主研发的深度学习平台,自2016年起正式开源给专业社区。它是一个拥有先进技术和丰富功能的工业平台,涵盖核心深度学习框架、基本模型库、端到端开发套件、工具和组件以及服务平台。PaddlePaddle起源于工业实践,致力于工业化。它已被制造业、农业、企业服务业等广泛采用,同时为超过 1070 万开发人员、235,000 家公司和 860,000 个模型提供服务。凭借这些优势,PaddlePaddle已经帮助越来越多的合作伙伴将AI商业化。
受影响的代码:“`
def _wget_download(url, fullname):
# using wget to download url
tmp_fullname = fullname + “_tmp”
# –user-agent
command = f’wget -O {tmp_fullname} -t {DOWNLOAD_RETRY_LIMIT} {url}’
subprc = subprocess.Popen(
command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE
)
该漏洞源于 url 参数在未经适当验证或清理的情况下合并到命令字符串中的方式。如果 url 是从不受信任的来源构建的,则攻击者可能会注入恶意命令。
POC验证:
from paddle import utils
utils.download._wget_download(“aa; touch codexecution”, “bb”)
然后将执行以下命令:
wget -O bb_tmp -t 3 aa; touch codexecutioncodeexecution
利用此漏洞的攻击者可以使用运行代码的进程的权限在主机系统上执行任意命令。根据使用此代码的上下文,这可能会导致未经授权的访问、数据丢失或其他潜在的有害后果。
修复patch:
**05**
AI供应链漏洞(CVE-2023-6778)
ClearML 是一个开源平台(之前叫TRAINS),可为全球数千个数据科学团队自动化并简化机器学习解决方案的开发和管理。
“项目描述”和“报告”部分中使用的 Markdown 编辑器组件未应用适当的数据清
理。
当未经筛选的数据传递到此组件时,它允许注入恶意 XSS 有效负载。
具体而言,此漏
洞存在于“项目描述”和“报告”部分中,使其容易受到存储的 XSS 攻击。
在项目描述的情况下,在创建项目并输入其名称和描述后,在概述中,项目描述直接传递到文件中的这一行
:
/app/webapp-common/project-info/project-info.component.ts
this.info = project.description;
然后
在这里
渲染:
<sm-markdown-editor
#editor
*ngIf=”!loading”
[class.editor]=”editor.editMode”
[data]=”info”
[readOnly]=”example”
(saveInfo)=”saveInfo($event)”
<div no-data class="flex-middle overview-placeholder" *ngIf="!example"> <i class="icon i-markdown xxl"></i> <div class="no-data-title">THERE’S NOTHING HERE YET…</div> <button (click)="editor.editClicked()" class="no-data-button btn btn-neon"> <span>ADD PROJECT OVERVIEW</span> </button> </div>
“`
以下视频演示了如何成功利用此漏洞,重点介绍如何生成应用凭据:
此漏洞具有重大的安全隐患,因为它可能导致用户帐户泄露和操纵应用程序中的各种关键功能。此漏洞的潜在影响包括:
1.用户配置文件操作:攻击者可以利用存储的 XSS 修改应用程序内用户的配置文件名称。这可能会导致冒充、身份盗用和用户混淆。
2.项目删除:通过使用 XSS 有效负载,攻击者可以强制受害者删除其项目,从而可能导致数据丢失和应用程序功能中断。
3.应用凭据滥用(在 POC 视频中演示):此漏洞的最严重后果是能够使用受害者的帐户生成应用凭据。应用程序凭据通常在应用程序中具有重要权限,允许用户执行各种管理操作。
使用泄露的应用凭据,攻击者可以:- 创建管道,这可能会导致未经授权的数据处理。
-
连接 ClearML 代理,可能会损害机器学习操作的完整性。
-
删除模型,导致潜在的数据丢失和系统中断。
-
以与受害者相同级别的权限执行其他操作,从而破坏应用程序的整体安全性和稳定性。
转载翻译汇总文献图片来源:
[1]huntr – 世界上第一个用于 AI/ML 的漏洞赏金平台:https://huntr.com/
[2]Protect AI | Home:https://protectai.com/
[3]赵月,何锦雯,朱申辰等.大语言模型安全现状与挑战[J].计算机科学,2024,51(01):68-71.
[4]警惕Hugging Face开源组件风险被利用于大模型供应链攻击 – 腾讯安全应急响应中心 (tencent.com)
学习安全五年+,挖洞、传统攻防、安全科研,欢迎扫码了解,有学生优惠