【论文速读】| SV-TrustEval-C:评估大语言模型中的结构和语义推理以进行源代码漏洞分析
【论文速读】| SV-TrustEval-C:评估大语言模型中的结构和语义推理以进行源代码漏洞分析
原创 知识分享者 安全极客 2025-06-11 09:19

基本信息
原文标题:SV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis
原文作者:Yansong Li, Paula Branco, Alexander M. Hoole, Manish Marwah, Hari Manassery Koduvely, Guy-Vincent Jourdan, Stephan Jou
作者单位:University of Ottawa, †OpenText
关键词:大语言模型,漏洞分析,结构推理,语义推理,SV-TrustEval-C,基准评测,C语言,自动化安全,代码安全
原文链接:https://arxiv.org/abs/2505.20630
开源代码:
https://huggingface.co/datasets/LLMs4CodeSecurity/SV-TrustEval-C-1.0
论文要点
论文简介:
随着大语言模型(LLM)在代码理解与生成领域能力的快速跃升,业界希望将其应用于源代码漏洞检测、修复等软件安全关键场景。然而,现有的评测往往只关注模型能否“检测/修复”某些典型的已知漏洞,并未深入考量其真正理解代码结构与内在语义的推理能力。
为填补这一空白,该论文提出了SV-TrustEval-C——一个专门针对C语言代码漏洞分析的推理能力测评基准。该基准围绕两大核心维度:结构推理(即模型对复杂数据流、控制流关系的理解能力)和语义推理(即模型在代码发生变化、嵌入混淆或功能目标调整等情境下的逻辑一致性与鲁棒性),通过自动代码变体生成器和针对推理过程精心设计的问题样例,全面考察主流LLM在各类真实与合成场景下的漏洞发现与评估能力。
论文的大规模实验显示,现有模型对于结构与语义复杂的代码理解仍严重依赖训练时的模式匹配,在实际安全推理任务上远未达“可信”水平。SV-TrustEval-C为未来LLM安全推理相关研究提供了更具解释性、可扩展和可细粒度分析的标准评测工具。
研究目的:
当前大语言模型虽已在代码生成与初步漏洞检测等任务上展现出巨大潜力,但依赖的多为训练中记忆的模板及简单模式,缺乏对代码内部复杂结构与运行机理的真实理解。这种模式匹配式的能力一旦遇到结构扰动、语义变异或组合型功能目标,便易失效,难以满足真实世界高可信、强泛化需求。以往主流评测基准,如BigVul、CVEFixes、DiverseVul等,更多着眼于“已知漏洞”的检测与修复成功率,而未能区分模型解决问题时究竟利用了深层逻辑推理还是仅仅借助现成记忆。
论文正是针对这一关键痛点,明确提出亟需一种新型基准,不只是关注“能否识别漏洞”,而是要能区分模型对代码结构、数据流及复杂上下文的细致理解和逻辑推理能力,真正支撑安全领域面向未来的自动化漏洞分析。SV-TrustEval-C的设计初衷,即在构造具挑战性、多变体、高精度标签的测评体系基础上,促进LLM漏洞分析能力的系统性、可信评测与有针对性的提升。
研究贡献:
-
基于推理的漏洞分析基准测试:研究者提出了SV-TRUSTEVAL-C,这是首个旨在通过逻辑推理和结构理解来评估大语言模型(LLMs)分析源代码漏洞能力的基准测试,超越了单纯的模式识别。
-
面向结构的变体生成器:研究者创建了一个生成器,该工具基于安全与不安全代码对,通过系统提取结构信息、改变代码语义,并依据数据和控制流图增加代码复杂度。
-
识别大语言模型能力差距:对11个大语言模型的评估显示,它们在漏洞分析中更依赖模式匹配而非逻辑推理,这凸显了在安全应用中增强其推理能力的必要性。
引言
近年来,大语言模型(LLM)取得了突破性进展,特别是经过代码领域专门预训练与精调的模型极大推动了自动化编程、代码理解、代码补全等任务的进步。得益于如Amazon CodeWhisperer、GitHub Copilot等商用系统,大量开发者已经体验到LLM带来的生产力提升。随之而来,学界与业界开始探索其在更高安全要求的领域——如代码漏洞分析——中的作用。与依靠静态或动态分析的传统工具不同,LLM有望在编写阶段实时提供安全反馈,甚至自动生成无漏洞代码,从而大幅提升开发安全性、防患于未然。
然而,实践表明,LLM在实际应用中并未保证生成代码的安全性,甚至容易输出语法正确但存在安全隐患的代码,这引发了对其安全分析能力可靠性的广泛担忧。以往对LLM漏洞检测能力的评估,主要借助CVEFixes、BigVul、DiverseVul等大型公开数据集,关注模型对已知简单漏洞(如缓冲区溢出等)的检测准确率或自动修复能力,但忽略了深层逻辑推理和结构理解的考察。更为关键的是,这类评测无法区分模型是借助其记忆的“概率分布”和“模式”给出答案,还是能够基于对复杂控制逻辑、数据流、真实语义的理解进行推理。前者难以在遇到超出训练分布或混淆、变形后的代码时展现出可信的泛化能力,这对于高安全场景来说是致命缺陷。
论文因而提出,一项合格的LLM代码安全评测体系,必须能够量化模型在结构推理(理解程序各要素间的数据流、控制流关系)、语义推理(在结构或语义扰动、目标变更等情况下的逻辑一致性和分析鲁棒性)两个核心维度的能力。为此,SV-TrustEval-C基准利用自动化变体生成、结构与语义场景定制、系统一致性度量等新方法,全面评测主流LLM对C语言漏洞分析的通用性与可信度。论文通过大量实验发现,当前模型普遍在结构关系理解、语义一致性、推理一致性等方面表现不佳,且容易因简单扰动而偏向错误分类。该基准的提出为今后的模型研究与产业安全自动化应用树立了更为严格和解释性强的能力底线。
相关工作与背景综述
传统的源代码漏洞检测多以人工代码审查为主,效率低下且易受人员经验影响。自动化工具如静态分析(FindBugs、PMD、Checkstyle等)和动态分析(如Fuzzing)通过程序语义与运行轨迹分析,提升了检测准确性和效率。近年来,机器学习与深度学习方法相继涌现,GNN、RNN等模型已被成功应用于漏洞检测,并促进了如Devign、VulPatchPairs等高质量数据集建设。
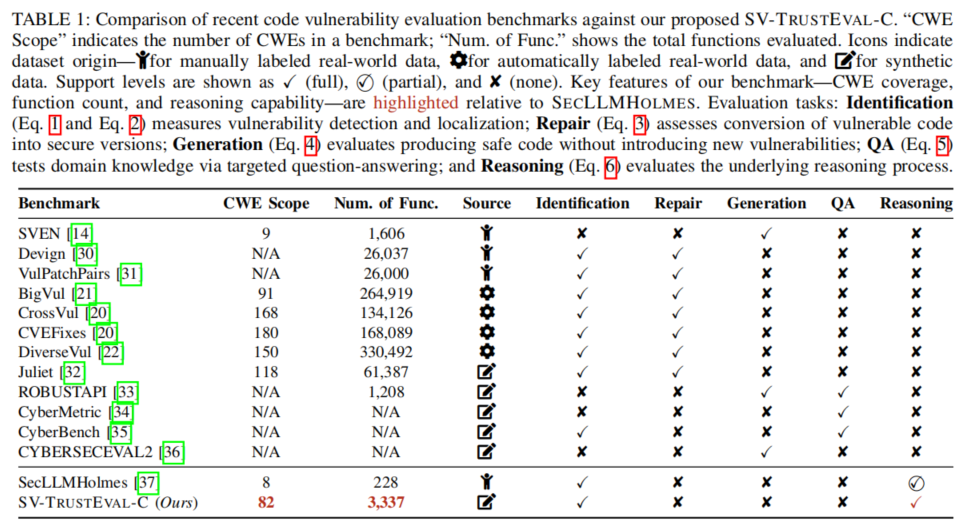
目前可用于漏洞分析领域的基准,主要涵盖五类任务:漏洞识别、漏洞修复、安全代码生成、问答与解释、推理能力评估。大部分基准,如BigVul、CVEFixes、DiverseVul等,聚焦对公开漏洞代码的二分类判断及修复能力,体现模型在现实仓库代码下的基本判别力。但这些基准更适合评估模型对历史知识的覆盖度,难以剖析其推理路径与泛化底层逻辑。
近年有学者尝试超越传统“检测/修复”评测,转向对LLM推理能力的探索。SecLLMHolmes引入手工设计的高难度推理场景,强调辨析模型是否真正利用结构和语义分析做决策;CodeMind与CRUXEval评估模型对输入输出、运行路径的推断,但更偏重程序功能正确性而非安全特性。另一方面,数据集质量亦是影响评测可信度的关键维度。BigVul、CrossVul等采用自动标签方法,存在标注不精与语义简化的局限;而完全手工标注如Devign虽准确但样本有限;合成数据(如Juliet Test Suite、Romeo)可确保标签精度,但需合理增强结构复杂度以贴合真实情境。
总体来看,业界对于LLM能否真正实现“可信安全自动化分析”这一目标尚缺少系统性、细粒度、可解释和高复杂度的能力评测工具。本论文基于上述洞察,从推理本质与安全目标出发,提出了能同时考查结构/语义推理双维度能力的SV-TrustEval-C,填补了现有基准普遍存在的短板并推动方法创新于数据/任务/评测的联动升级。
SV-TrustEval-C基准设计与实现
SV-TrustEval-C围绕可靠漏洞分析所需的两大能力——结构推理与语义推理——展开设计。其核心理念是在合成与变化丰富的高质量代码样本上,通过自动化问题生成和精细标签归类,激发并量化模型对真实安全场景的分析与推理极限。

首先,结构推理方面,基准区分数据流与控制流两个子维度。数据流推理着重于模型能否理解变量赋值、参数传递等信息在程序中的传播路径;控制流推理则考查模型识别条件分支、循环等流程,及其对函数执行结果的直接/间接影响的能力。每一道结构推理题都要求模型判断特定代码元素之间是否存在直接、间接或无关联,难度随跳跃关系(hop数)增加而递进。
语义推理侧重模型在代码语义扰动、目标调整等情境下的鲁棒性与逻辑一致性。作者设计了三类典型推理任务:反事实(Counterfactual)、目标驱动(Goal-driven)、预测(Predictive)。反事实任务让模型判断当代码结构/语义被修改后是否仍会触发目标漏洞,并区分安全、危险与功能受损三种变体;目标驱动要求模型在修复漏洞的同时保持原始功能,考验其实现安全与功能兼容的能力;预测任务则挑战模型对不同安全状态(有/无漏洞、不同比例损失功能等)进行精确分类。
为支撑高复杂度问答与样本多样性,论文开发了结构导向的变体生成器。其利用AST解析、数据流与控制流图自动提取功能元素,并对同一基础代码合成若干结构与行为均有变化或嵌套的“安全/危险/功能受损”多重变体。其加入的控制流注入(如增加外部分支、嵌套结构等)极大扩展了问题难度与场景覆盖广度。每个基准问题均附有明确选项及唯一正确答案,支持系统性的一致性与能力细粒度考察。
最终,SV-TrustEval-C基于C语言Juliet Test Suite 377个基础代码文件(含82类CWE),自动生成1297个危险、1286个安全可编译变体,组合出9401道结构与语义推理题。标注全流程实现100%准确标签,场景密度和难度远超以往类似评测。工具链和数据开放,便于多语言扩展和新场景再造。
实验设置与评测方法
论文系统评估了11种参数规模与预训练源多样的主流LLM,包括GPT-4-turbo、GPT-3.5-turbo、Llama3.1(405B/8B)、CodeLlama(13B/7B)、Gemma(7B)、CodeGemma(7B)、CodeQwen1.5(7B)、Mixtral(7B)等。所有模型均为“instruct”版本,经过代码相关领域精调以增强指令遵从与任务适应。评测时统一设定temperature=0,最大发电长度50 token,确保输出唯一性与可对齐性,多任务采用完全隔离的会话实现QA防泄漏。
推理方式分为zero-shot(直接基于单道题目输入推理)及in-context learning(加入示例题-答-解释的few-shot预热),以考察模型本身推理能力与上下文激励对表现的影响。每道题的输入模板经过专家与LLM多轮筛选优化,保证问题表述规范清晰、多样化且无标签泄漏。为阻断模型对Juliet等公开数据标记字段的记忆影响,所有基础代码样本均进行了变量/函数名泛化、敏感注释消隐等处理。
测评主要指标为准确率(Accuracy)、结构/语义推理一致性分数(Consistency),并辅助记录对安全/安全样本的误报率FPRsafe。实验流程覆盖各类推理题型/难度的全面交叉对比,支持pairwise对比(成对安全/危险变体联合输入)与单题输入两种模式,确保细粒度和广度兼顾。
实验结果与分析
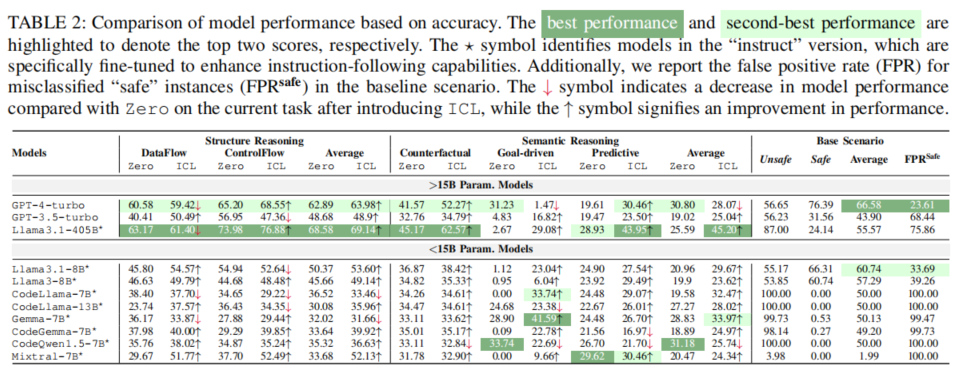
大规模实验结果显示,LLM在结构推理任务(数据流/控制流)中的表现,明显随模型规模增加而提升。例如,Llama3.1-405B在zero-shot和in-context learning下均超过68%,显著优于GPT-4与所有中小规模同行。然而,一旦到了需要深层语义推理与一致性能力的反事实、目标驱动、预测类题,所有模型平均分数均低于32%(zero-shot),即使in-context learning辅助后也未超过46%。特别是在目标驱动题(修复漏洞且保留功能),几乎所有LLM准确率和一致性都极低。
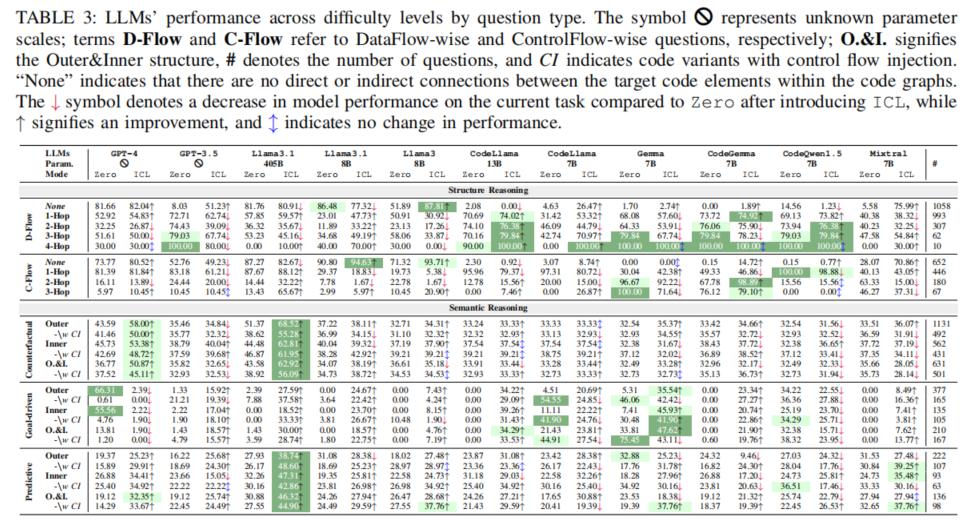
进一步分析发现,绝大多数模型在漏洞分析时,本质依附于已见模式和表层特征对齐,对结构扰动或语义变异缺乏稳健的逻辑推理力。大量数据流/控制流题目中,部分小模型倾向于判定所有元素均存在某种联系,凸显欠缺逻辑型判别机制。引入复杂嵌套与分支结构(如control flow injection)时,绝大多数模型准确率显著下降,暴露出对结构变化的极强敏感性与推理能力薄弱。
值得注意的是,对于安全性判别任务,部分模型对“安全样本”的误判率极高(如CodeLlama、CodeQwen等接近100%将安全代码归为危险),这是过度模式泛化的典型表现。引入in-context learning可对部分模型起到提升作用,尤其如Mixtral、Llama3.1-8B等规模偏小但指令跟随较弱的模型性能增幅显著;但对于如GPT-4在目标驱动任务上反有降分,说明该领域上下文激励需进一步专业定制与场景适配。
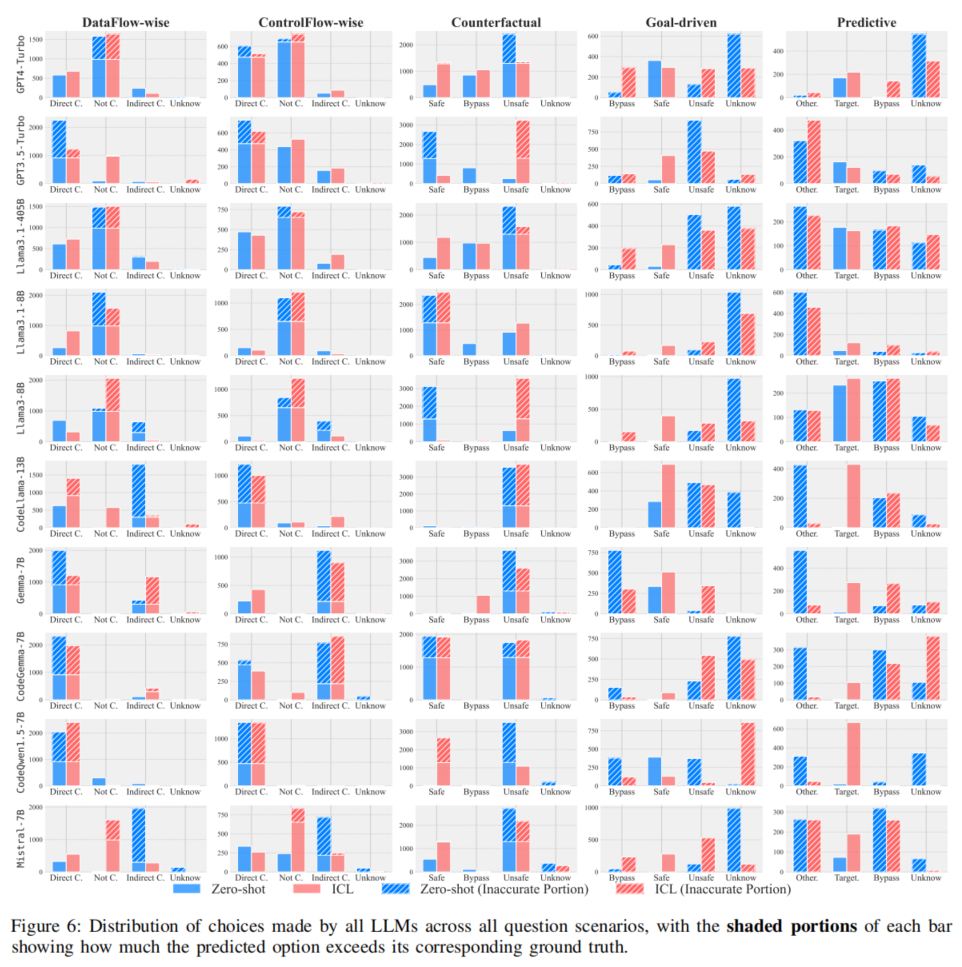
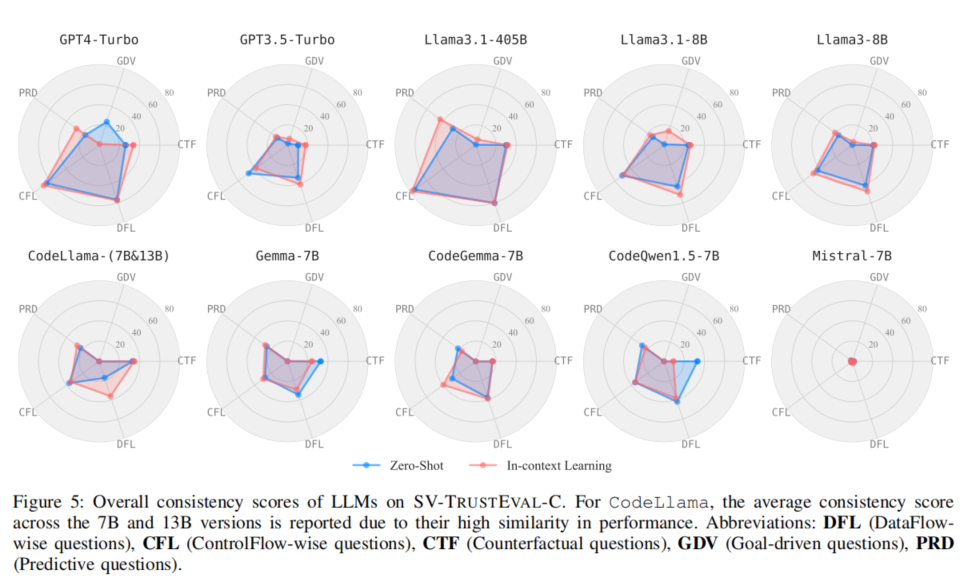
一致性分析显示,结构推理下,GPT-4及Llama3.1-405B能够维持较高的输入输出关系一致,反映其结构理解力优于同类。但所有模型在语义推理场景下表现出系统性一致性不足,尤其在要求对不同变体、不同CWE下做逻辑等价输出时,难以正确迁移基础知识。例如,即便准确识别原始漏洞样本,语义扰动后极易做出相逆判断,说明抽象能力和推理迁移是LMM动力学机制的深层短板。
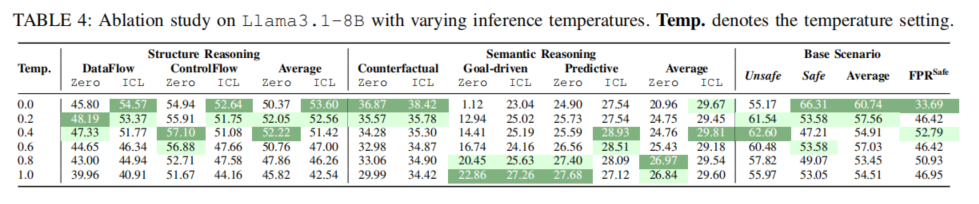
此外,论文还进行了温度调参、pairwise对比以及基于不同CWE任务层次的差异分析。发现低温度有助于结构型一致输出,而适当温度提升有利于复杂推理题的解耦与回答多样性;pairwise输入提升基础二分类的准确,却因偏移模式现象在高复杂推理下反而更易失效;复杂CWE如缓冲区溢出、输入校验等场景下模型误判率显著高于低复杂场景,需未来进一步针对性提升。
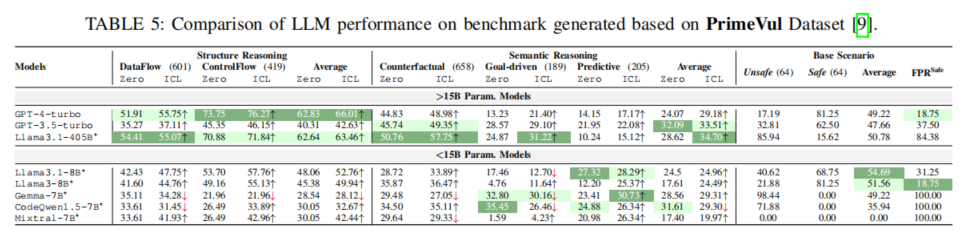
实验还将基准应用至PrimeVul等多样化数据源,实现自动构造高质量安全/危险样本,结果验证SV-TrustEval-C具备良好跨数据集的可扩展性和适应能力。
论文结论
本文提出的SV-TrustEval-C基准,为大语言模型在源代码安全漏洞分析场景下的结构推理与语义推理能力评测提供了全新的系统性工具。全方位实证显示:当前主流LLM(即使如GPT-4)在漏洞分析问题中主要依赖训练记忆的模式匹配,难以在复杂结构或语义扰动下展现出稳定、可靠的逻辑分析与泛化能力;模型对安全样本误判严重,对“Bypass”等简单手法极易被迷惑,显示出现有技术路径尚不适合直接部署于高要求安全实际场景。论文所发布的评测基准和配套工具,不仅对LLM研究社区、自动化安全工具产业具有重要参考价值,更揭示了未来提升模型可信推理力与领域知识迁移能力的关键方向。后续工作计划将拓展基准至更多编程语言及更复杂多样的实际开发情景,支撑业界和学界对可信AI自动化安全的持续深挖与应用创新。

