【论文速读】| FuncVul——基于LLM与代码块的高效函数级漏洞检测模型
原文链接: https://mp.weixin.qq.com/s?__biz=MzkzNDUxOTk2Mw==&mid=2247496737&idx=1&sn=370c593f1bce328f065b2ee3561a83bb
【论文速读】| FuncVul——基于LLM与代码块的高效函数级漏洞检测模型
原创 知识分享者 安全极客 2025-07-01 10:22

基本信息
原文标题:FuncVul: An Effective Function Level Vulnerability Detection Model using LLM and Code Chunk
原文作者:Sajal Halder, Muhammad Ejaz Ahmed, Seyit Camtepe
作者单位:Data61, CSIRO, Australia
关键词:函数级代码、漏洞检测、代码块、软件供应链、大语言模型
原文链接:https://arxiv.org/abs/2506.19453
开源代码:https://github.com/sajalhalder/FuncVul
论文要点
论文简介:本文关注于软件供应链环境下的源代码漏洞检测,提出了一种创新的函数级漏洞检测方法FuncVul。相较于现有的主要针对整体包或库级别进行检测的方法,FuncVul聚焦于函数级别并进一步定位到函数内部的代码块,以实现对具体漏洞行的精准发现。该方法利用了大语言模型(LLM)和补丁(patch)信息自动标注高质量数据集,并基于预训练且支持结构化代码输入的GraphCodeBERT模型进行微调,实现了对C/C++和Python代码中多个漏洞点的识别。论文构建了六套不同类型的数据集,采用基线方法和多维度指标系统地开展对比评测。
实验表明,FuncVul在不同数据集上均获得了87%-92%的准确率和86%-92%的F1分数,并对基于整个函数的检测方法带来了显著提升。研究还探讨了泛化性、对未知项目漏洞的检测能力及最佳代码块长度等问题。该方法及其数据集均已开源,促进了后续研究与应用落地。
研究目的:本研究旨在解决现有函数级漏洞检测难以精确定位内部多处漏洞、难以指示具体存在问题的代码行以及泛化能力有限等挑战。作者尝试通过“基于代码块的建模”而非整体函数粒度,利用LLM高效生成带标签的训练数据,结合GraphCodeBERT精准捕获代码语法与语义特征,实现以下目标:(1)准确检测函数级漏洞并定位漏洞代码块,(2)衡量代码块方法相较全函数分析的性能优势,(3)提升模型对不同项目和未知补丁场景的泛化能力,(4)探索最佳的块划分策略以及能否在单个函数内部发现多个漏洞点。
研究贡献:
– 研究者提出了一种新颖的基于代码块的函数漏洞(FuncVul)检测模型,该模型能够识别函数内的多个漏洞,并且重要的是,能够定位导致这些漏洞的具体较小代码段。
-
研究者从多种数据源收集并整理了四个数据集,例如来自 GitHub 的项目源代码和漏洞公告数据库(如 OSV)。此外,研究者开发了新方法,利用大语言模型(LLMs)对源代码进行分析、处理和整理。
-
研究者采用了微调后的 GraphCodeBERT 模型进行函数级漏洞预测,因为它能有效捕捉代码中的语法和语义相似性。
-
实验结果表明,所提出的 FuncVul 模型性能优于最先进的基线模型,在六个数据集上实现了平均 89.39% 的准确率和 88.94% 的 F1 分数。
-
此外,研究者还证明了 FuncVul 模型具有高度通用性,能够处理多样化的代码块并有效识别新的漏洞模式。
引言
当前,随着技术快速发展和软件复杂性的持续提升,软件供应链安全在业界与学术界都成为广泛关注的研究重点。国家漏洞数据库(NVD)截至2024年10月已累计收录24万多个CVE漏洞,且该数字每年平均增长15-20%。对C/C++和Python等主流编程语言进行准确漏洞检测,对保障软件供应链安全具有重要意义。然而,传统方法通常集中于检测整个包或库是否存在漏洞,难以精确定位具体函数甚至是代码行级的风险。更进一步,即便能够识别到漏洞函数,往往也无法揭示函数内部具体存在问题的代码段。此类粒度粗、定位不精的特性,导致开发者在修复时需手动代码审查,增加了维护难度和时间成本。
面对数量庞大、分布广泛的开源包和函数,人工分析无疑代价高昂且难以大规模应用。因此,急需能够自动、精确、高效定位关键函数及其漏洞代码块的检测方法。与此同时,现有学术界方法虽然采用了机器学习、深度学习与图神经网络等手段,但仍存在两个显著不足:一是只能给出函数级二分类结果(是否含漏洞),难以进一步指示漏洞具体行和数量;二是受限于模型粒度和数据采集方式,实际定位能力与泛化能力有限。
鉴于此,本文提出了一种创新性的基于代码块的函数级漏洞检测框架FuncVul。作者设计了以“代码块(code chunk)”为基本检测单元的新颖方法,并通过LLM自动生成高质量带标签的数据集,结合对预训练模型的适配微调,实现了函数级漏洞多点、精定位检测与全面评估。论文系统讨论了该方法在提升检测准确性、缩短修复时间及提高泛化能力等方面的有效性,并通过实验证实了其显著优势。引言中还明确提出了六个关键研究问题(RQ1-RQ6),覆盖了核心建模策略、代码块方法优越性、泛化能力、复杂场景适应性与多点检测能力,彰显了本文系统、全面推进函数级漏洞检测技术前沿的学术追求。
相关工作与背景
软件漏洞检测是软件工程与网络安全领域的核心问题。相关研究主要沿两个方向展开:一是漏洞检测算法与模型,二是漏洞数据集的创建。现有方法涵盖了传统的特征工程与机器学习(如TF-IDF加轻量模型)、深度学习(如BERT、RoBERTa、LSTM等语言模型)、基于图的神经网络(如Graph Neural Networks, GNNs)、上下文嵌入、以及近年来兴起的大语言模型(LLMs)等。
代表性工作如Hanif等提出的VulBERTa基于RoBERTa模型,针对C/C++代码训练,充分挖掘代码语法与语义;Warschinski等提出的VUDENC利用Word2Vec与LSTM完成Python代码的漏洞序列识别;Yuan等则结合GRU与图网络提取代码多维特征并用随机森林支持不平衡样本,获得优异检测性能。Wang等开发了大规模仓库级数据集ReposVul,并形成用于流程化语义抽取的工具链。Li等开发了VulPecker工具,采用基于补丁特征与代码相似度的模式检测策略。Transformer和BERT模型,如LineVul,能利用深度上下文建模进行更细粒度的漏洞预测。GNN相关工作(如Devign、AMPLE等)通过图结构深入挖掘源代码的数据流、控制流和依赖关系。
然而,大部分方法主要关注于函数级二分类,即判断函数是否存在漏洞,对内部漏洞数量及具体位置尚无法充分挖掘,导致开发者补丁定位与修复代价高。此外,部分方法能达到更细粒度的行级检测(如LineVul),但受限于语义捕捉能力与模型泛化性,实际检测效果有限。
随着LLM模型(如BERT、GPT、Gemini等)在各领域应用日益广泛,学界也开始将其用于漏洞检测,如GRACE 工作利用图结构与语境学习提升LLM检测精度;Akuthota等直接利用LLMs完成漏洞监测任务。与这些先前工作不同,本文首次提出利用LLM配合补丁自动高质量标注训练集,并以代码块为单元结合GraphCodeBERT微调,实现对函数内部多个漏洞、未知项目及新型漏洞的全面、精准检测,具有明显的创新优势。
预备知识与问题定义
为支持新型方法的提出,论文首先明确了若干基础概念。函数代码块(Function Code Chunk, FC)被定义为函数源码内一段连续代码行,通常围绕代码变更(如补丁更新)为中心,并包含变更前后各若干行,以便保留关键上下文。泛化代码块(Generic Code Chunk)则指将函数名、变量名等具体标识符统一用通用占位符(如F1、V1等)替换后的代码块,这样可消除由开发风格、命名差异导致的数据偏差,增强模型泛化性与鲁棒性。
特别地,3-行扩展代码块是以代码编辑行为中心,上下各扩展三行的代码片段,用于最大程度保留漏洞行的语义上下文。若补丁修改远多于10行,则只取变更相关的全部行而不做进一步扩展。
基于上述定义,本文将函数级代码块漏洞检测问题形式化为:给定C/C++或Python代码对应的带补丁修改信息的函数代码块,设计一个检测器V,使得V能自动判别该代码块是否包含漏洞(1为有,0为无)。论文以高质量的代码块构建与泛化、自动标签生成、以及精细建模为核心,系统推进了该难题的解决。
数据集构建与模型方法
论文在数据集构建与方法设计方面进行了系统创新。首先,在数据集方面,作者开发了一套半自动标注机制,综合利用补丁信息和LLM能力。通过从GitHub代码和OSV等漏洞库中爬取项目及补丁,提取单一修改的函数变更(确保只有一处相关修改提升标签精度),再利用Gemini 1.5 Pro等LLM模型对每一代码块生成“脆弱/安全”标签,并指示具体漏洞行。代码块分为原始块和泛化块两种,结合不同的LLM提示词,最终产出六套多样化数据集,覆盖不同语言、抽象层次和细分场景。
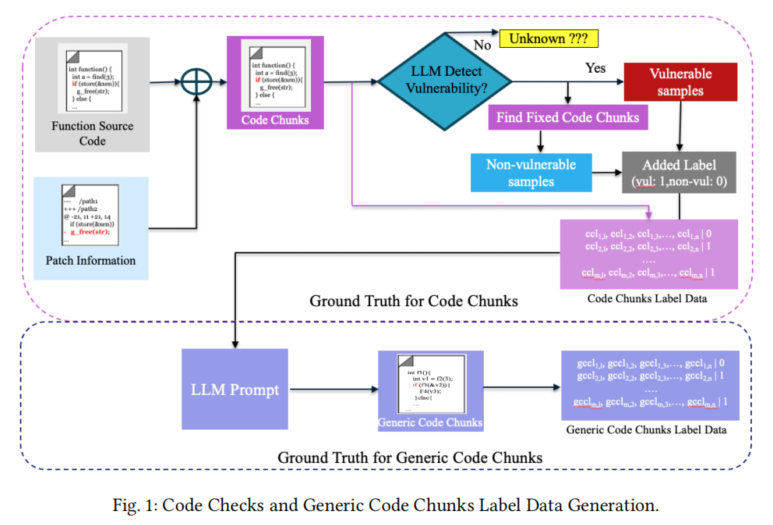
对于标签生成,论文提出一套交叉验证机制:先用补丁信息过滤出高置信度的单点修改,再由LLM对照CVE描述自动判断违规代码行,并要求其与补丁删除行有重叠才判定为漏洞样本。未满足标准的样本则标记为“未知”并筛除。负样本则由修复后的代码块或随机关联无风险块构造而成,保证样本质量和分布平衡。
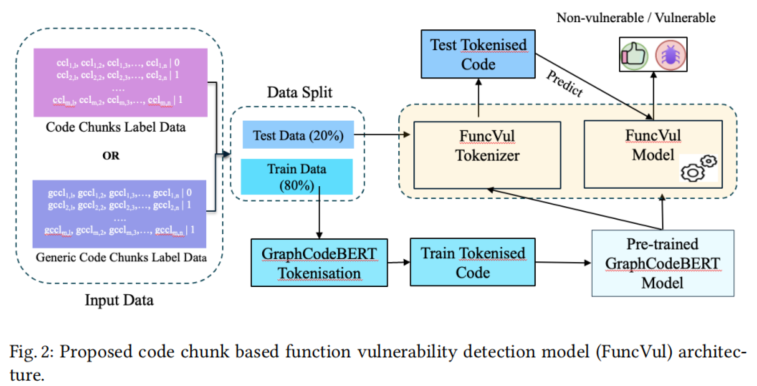
在模型方法层面,核心为以GraphCodeBERT为主体的微调框架。GraphCodeBERT作为支持数据流建模的高性能代码预训练模型,能捕捉代码语义结构及上下文依赖。训练流程为:将生成的带标签代码块分为80%训练、20%测试,利用GraphCodeBERT的tokenizer和模型对块数据进行编码、训练与优化,最终得到名为FuncVul的专用检测模型。推理过程中,新样本亦经Token化后由微调后的FuncVul判别其漏洞风险,并可返回判定理由。整体流程包括数据集构建、自动标签生成、块处理、泛化、模型训练与推理全流程,支持批量、自动化漏洞检测与多代码块并行处理。
实验设计与结果分析
实验设计严格对标方法提出的六个关键研究问题(RQ1-RQ6)。实验平台为Python环境,MacBook Pro(Apple M3, 24GB RAM),模型关键参数为batch size=8、编码维度512、3轮训练、warmup steps=50、权重衰减0.05。所有数据均采用80/20划分并做5折交叉验证,评价指标包括准确率、精确率、召回率、F1分数和MCC,能全面反映模型性能。
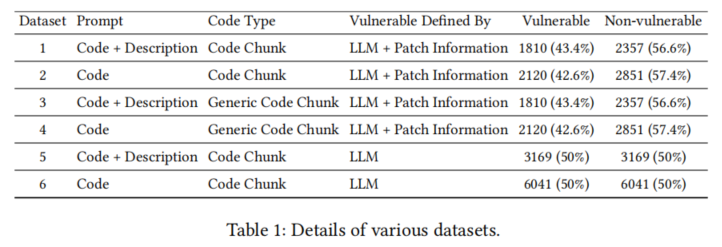
六套数据集覆盖原始代码块、泛化代码块、多种标注与负样本采样。其中前四套基于补丁与LLM双重标签,第五、第六套则直接用LLM提取漏洞行并自动分块,均衡覆盖不同主流编程语言与真实修复案例。
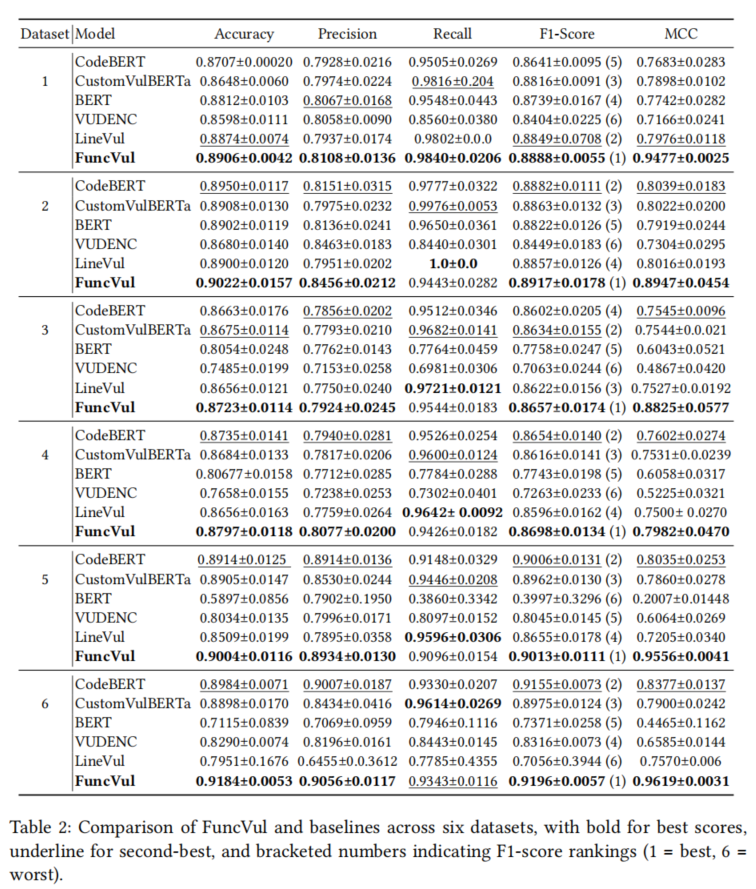
与五个强劲基线(CodeBERT、CustomVulBERTa、BERT、VUDENC、LineVul)对比实验表明,FuncVul在绝大多数指标和实验场景下均稳居第一,准确率区间为87%-92%,F1分数区间为86%-92%,远优于函数整体建模方法。以Dataset 1为例,块级建模在准确率上提升高达53.9%,F1分数提升42%。泛化代码块的实验结果虽略逊于原始块,但仍达到高水平,且具更强实时适配性。对于完全“未知补丁”、“新项目ID”等泛化挑战集,FuncVul依然取得了81.95%-76.69%的准确率和90%以上的召回,显示了良好的领域迁移性能。扩展不同块长度的实验进一步显示,3-行扩展块为最佳折中,既提供足够上下文,又不引入冗余干扰。
此外,通过分块方式可自动拆解同一函数内的多个漏洞点——这一能力为函数级检测带来了全新可能。实验中,FuncVul有效捕捉并定位了复杂函数内多处高风险区域,极大减轻了专家人工定位难度。
论文结论
本文提出了一种创新性的函数级漏洞检测模型FuncVul,结合了补丁感知的高质量数据生成机制、基于代码块的精细划分策略以及大规模预训练模型(GraphCodeBERT)的微调能力,实现在C/C++和Python代码环境下对函数内部多个风险点的精准检测。通过系统性实验,FuncVul在各类真实数据集上均显示出卓越性能,远超现有主流方法,尤其是在定位精度、泛化能力及多漏洞检测等方面展现了独特优势。论文亦表明三行代码扩展块的策略效果最佳,数据泛化与模型迁移兼具高效和准确。所有实验流程、数据与代码工具已公开,为软件供应链安全、自动化漏洞修复和学术研究开辟了新路径。
研究亦坦陈当前尚未探究多类别漏洞风险分级问题,以及仅覆盖C/C++和Python两类主流语言。未来,作者计划进一步拓展到更多编程语言,尝试多分类检测、多标签风险评估,并结合漏洞严重度、优先级等需求,提升实际应用价值与自动化水平。FuncVul的提出和开源,将为软件安全、代码智能分析及训练数据共享提供持久支撑,推动自动化漏洞检测技术的实用落地与学科进步。

